

Tại sao các ứng dụng trên điện thoại có thể hiểu được những gì bạn nói? Đó chính là nhờ vào một nhánh của trí tuệ nhân tạo vô cùng mạnh mẽ: Machine Learning. Nghe có vẻ phức tạp, nhưng thực tế, các thuật ngữ trong Machine Learning có thể được giải thích một cách đơn giản và dễ hiểu. Hãy cùng SlimCRM khám phá nhé!
Phần 1: Phân biệt AI, Machine Learning và Deep Learning
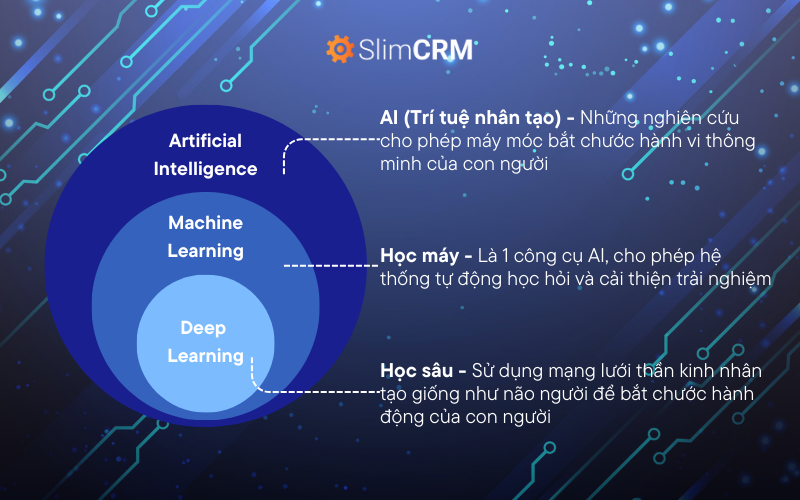
1. AI - Sự mô phỏng trí óc con người trong một hệ thống máy móc
Khái niệm
Để phân biệt AI, Machine Learning và Deep Learning, trước hết bạn cần hiểu AI hay Trí tuệ nhân tạo là gì? AI (Artificial Intelligence), hay trí tuệ nhân tạo, là một ngành của khoa học máy tính chuyên về tự động hóa các hành vi thông minh. Đây là một lĩnh vực dựa trên các nguyên lý lý thuyết vững chắc và khả năng ứng dụng thực tiễn, nhằm mô phỏng trí tuệ con người trong hệ thống máy móc.

Nói cách khác, AI là trí tuệ được con người tạo ra để giúp máy móc có khả năng tư duy, suy nghĩ và học hỏi như con người. Điểm nổi bật của AI là khả năng xử lý dữ liệu nhanh hơn, quy mô lớn hơn, có tính hệ thống và khoa học hơn so với trí óc con người.
Phân loại
- AI hẹp (Narrow AI) là loại AI phổ biến nhất hiện nay và được thiết kế để thực hiện một nhiệm vụ cụ thể, như nhận diện khuôn mặt hoặc chơi cờ.
- AI tổng quát (General AI) có khả năng hiểu và thực hiện bất kỳ nhiệm vụ nào mà con người có thể làm. Tuy nhiên, loại AI này vẫn đang trong giai đoạn nghiên cứu.
Tổng Hợp Tất Cả Các Thuật Ngữ Trí Tuệ Nhân Tạo AI Mà Bạn Cần Biết
2. Machine Learning - Một phương pháp chinh phục AI
Khái niệm Machine Learning
Machine Learning (Học máy) là một phân nhánh của AI, tập trung vào phát triển các thuật toán và mô hình cho phép máy tính học dữ liệu mà không cần lập trình cụ thể.

Phân loại Machine Learning
- Học có giám sát (Supervised Learning): Máy tính được đào tạo trên một tập dữ liệu đã được gắn nhãn sẵn (chẳng hạn như hình ảnh kèm chú thích), từ đó học cách dự đoán nhãn cho những dữ liệu mới.
Các loại chính:
Classification (Phân loại): Dùng để phân loại dữ liệu vào các nhóm. Ví dụ, một mô hình phân loại email có thể phân loại email là “spam” hoặc không.
Regression (Hồi quy): Dùng để dự đoán các giá trị liên tục. Ví dụ, dự đoán giá bất động sản dựa trên diện tích và vị trí.
- Học không giám sát (Unsupervised Learning): Máy tính xử lý dữ liệu chưa được gắn nhãn để phát hiện các mẫu hoặc cấu trúc ẩn bên trong.
Các loại chính:
Clustering (Phân cụm): Các điểm dữ liệu tương tự được nhóm vào cùng một cụm. Ví dụ, trong kinh doanh, phân chia khách hàng thành các nhóm khác nhau dựa trên hành vi mua sắm để xây dựng chiến lược marketing phù hợp.
PCA và Association: PCA (Principal Component Analysis) được dùng để giảm số chiều của dữ liệu, giúp dễ quan sát và phân tích hơn. Association thường được sử dụng để tìm ra các mẫu hoặc mối quan hệ trong dữ liệu, ví dụ như trong các hệ thống gợi ý sản phẩm.
- Học củng cố (Reinforcement Learning): Máy tính học cách đưa ra hành động tối ưu thông qua việc nhận phản hồi liên tục từ môi trường.

3. Deep Learning - Một kỹ thuật để hiện thực hóa Machine Learning
Khái niệm
Deep Learning (Học sâu) là một phân nhánh của Machine learning, nó cho phép con người huấn luyện một AI có thể dự đoán được các đầu ra dựa vào một tập hợp các đầu vào. Vì vậy, Deep learning yêu cầu rất nhiều dữ liệu đầu vào và sức mạnh tính toán.

Deep learning tương tự một mạng thần kinh - neural networks, có thể xử lý dữ liệu tương tự như bộ não con người. Điểm khác biệt là con người không phải đào tạo một chương trình deep learning biết một chiếc xe ô tô nhìn như thế nào, mà chỉ cần cung cấp cho nó đủ hình ảnh cần thiết về xe ô tô. Sau đó, nó sẽ tự hình dung và tự học. Tóm lại, Deep learning có thể tự đào tạo chính nó.
Phân loại
- Mạng nơron tích chập (Convolutional Neural Networks – CNNs): Thường được dùng để nhận diện và phân tích hình ảnh hoặc video.
- Mạng nơron hồi tiếp (Recurrent Neural Networks – RNNs): Phù hợp cho việc xử lý dữ liệu dạng chuỗi như văn bản hoặc âm thanh, nhờ khả năng ghi nhớ thông tin trước đó.
- Mạng nơron sinh điều kiện (Generative Adversarial Networks – GANs): Dùng để tạo dữ liệu mới dựa trên dữ liệu gốc, chẳng hạn như tạo hình ảnh hoặc video giả lập.
4. Sự khác nhau cơ bản giữa AI, Machine Learning và Deep Learning
AI | Machine Learning | Deep Learning | |
Phạm vi và Khái niệm | Khái niệm rộng nhất, AI bao gồm tất cả các kỹ thuật và phương pháp nhằm tạo ra hệ thống có khả năng thực hiện các nhiệm vụ thông minh. | Là một phân nhánh của AI và một phương pháp để thực hiện AI | Là một phân nhánh cao cấp hơn của Machine Learning, chuyên dùng các mạng neuron sâu để phân tích và học từ dữ liệu. |
Phương pháp và Kỹ thuật | Có thể sử dụng nhiều phương pháp khác nhau | Sử dụng các thuật toán học máy để phân tích dữ liệu và học từ đó. | Sử dụng các mạng nơron sâu với nhiều lớp để phân tích dữ liệu. |
Ứng dụng và Tính năng | Có thể bao gồm các ứng dụng như trợ lý ảo và robot tự động. | Được sử dụng trong nhiều ứng dụng thực tiễn như dự đoán xu hướng thị trường, và phân tích hành vi khách hàng. | Thích hợp cho các ứng dụng cần xử lý dữ liệu phức tạp như nhận diện hình ảnh, dịch ngôn ngữ tự động, và phân tích video. |
Yêu cầu về Dữ liệu và Tài nguyên | Không nhất thiết phải yêu cầu một lượng lớn dữ liệu. | Thường cần một lượng dữ liệu vừa phải để học và phát triển mô hình. | Yêu cầu một lượng lớn dữ liệu và tài nguyên tính toán để huấn luyện các mạng nơron sâu. |
Khả năng giải thích và Tinh chỉnh | Dễ dàng giải thích và tinh chỉnh vì chúng dựa trên các quy tắc logic rõ ràng. | Khó giải thích hơn. Tuy nhiên, nhiều kỹ thuật như hồi quy tuyến tính hay cây quyết định vẫn có thể dễ dàng giải thích. | Khó giải thích. Sự phức tạp của các mạng nơron có thể làm việc cải thiện mô hình này gặp khó khăn. |
Phần 2: Tìm hiểu các khái niệm Machine Learning
Về cơ bản, Machine Learning là một hệ thống máy móc bắt chước cách con người học tập.
- Mô hình trong Machine learning giống như Học sinh
- Dữ liệu tương đương với Bài tập thực hành. Muốn học sinh tính diện tích thì phải cho bài tập diện tích. Tương tự, muốn máy làm gì thì phải huấn luyện cái đó.
- Tương tác với dữ liệu giống với Suy nghĩ và làm bài. Ví dụ, học sinh nhận bài tập thì suy nghĩ, làm bài còn mô hình nhận dữ liệu thì tương tác với dữ liệu để ra kết quả là dự đoán của mô hình.
- Hàm mất mát (loss function) và Giá trị thực tế (ground-truth): Nếu như giáo viên chấm bài dựa trên đáp án thì hàm mất mát đánh giá độ lệch giữa dự đoán của mô hình và giá trị thực tế. Càng lệch ít thì loss value càng nhỏ, chất lượng mô hình càng tốt.
- Giá trị mất mát tương ứng với bài tập đã được chữa. Giáo viên chữa bài cho học sinh rút kinh nghiệm, còn hàm mất mát trả về loss value để mô hình tự cập nhật và cải thiện.
- Minibatch giống một tệp bài tập. Học sinh làm nhiều bài tập cùng lúc, còn mô hình xử lý một cụm dữ liệu cùng lúc.
- Quá trình lặp lại: Tương tự vòng lặp Bài tập - làm bài - chấm bài - rút kinh nghiệm, hệ thống máy sẽ lặp lại quy trình từ Dữ liệu - tương tác - dự đoán - tính loss value - cập nhật mô hình.
- Dữ liệu chất lượng giống với một bài tập chất lượng. Bài tập phải liên quan và phù hợp với khả năng của học sinh. Dữ liệu cũng phải liên quan và phù hợp với khả năng của mô hình.
- Underfitting (Chưa khớp): Tương tự việc cho học sinh lớp 10 làm bài tập của sinh viên đại học, nếu dữ liệu quá phức tạp so với mô hình thì mô hình cũng không thể học được gì.
- Overfitting (Quá khớp): Nếu mô hình quá khớp so với dữ liệu thì dễ bị học vẹt, không tổng quát hóa được.
- Model weight hay Học có trọng tâm: Học sinh tập trung vào những phần kiến thức trọng tâm nhất. Model gán trọng số cao cho các đặc trưng quan trọng.
- Bias - Thiên vị, như học sinh chọn làm những bài tập đơn giản. Nếu có sự đơn giản hóa hoặc tập trung quá hẹp thì sẽ dẫn đến thiếu hụt kiến thức hoặc khả năng mô hình hóa.
- Variance: nếu quá phụ thuộc hoặc tập trung hóa vào dữ liệu hoặc kiến thức cụ thể, dẫn đến khó khăn khi đối mặt với tình huống mới, giống như học sinh học tủ một phần kiến thức sẽ gặp khó khăn trong bài thi.
- Token hóa đầu vào giống như việc chuyển lời nói của giáo viên thành văn bản để làm bài. LLMs (Large language model) hay Mô hình ngôn ngữ lớn “ghi chép” bằng cách chuyển đổi văn bản thành các token, giống như học sinh nghe giảng và ghi chép lại để hiểu bài.
- Cơ chế Attention là đọc hiểu trọng tâm: LLMs sử dụng cơ chế attention để ‘tập trung’ vào các token quan trọng, từ đó hiểu ngữ cảnh tốt hơn, giống như học sinh khi làm bài sẽ tập trung vào những phần quan trọng của đề bài.
- Lập luận từng bước, bước sau dựa trên kết quả của bước trước, giống như học sinh suy nghĩ và viết, câu sau dựa vào câu trước. LLMs sẽ dự đoán từ tiếp theo dựa trên các token trước đó.
- Vector Embedding tương tự việc dùng mẹo. VÍ dụ, bài thơ có vần để dễ nhớ dễ thuộc, học sinh dùng mẹo để học từ vựng. LLMs sử dụng vector embedding để ghi nhớ và biểu diễn thông tin, giúp truy xuất thông tin hiệu quả.
Chunking
(RAG - Augmented Generation, hãy tưởng tượng RAG như một thư viện thông minh, khi bạn đưa ra một yêu cầu, thủ thư sẽ giải đáp cho bạn. Tương tự như vậy, chuyên gia (LLM) sẽ đọc những cuốn sách đó và trả lời câu hỏi cho bạn)
- Chunking trong rang như học sinh chia nhỏ bài tập dài thành từng phần nhỏ để học. Chunking là quá trình chia tài liệu lớn thành các đoạn nhỏ hơn gọi là chunk.
- Chunk size giống độ dài của mỗi phần bài học. Nó có thể là một vài âu, 1 đoạn hay 1 vài trang tùy thuộc vào loại tài liệu và mục đích sử dụng.
- Tìm kiếm thông tin với chunks như việc học sinh tìm kiếm thông tin trong SGK. RAG (Retrieval - Augmented Generation) hay Tối ưu hóa truy xuất sử dụng chunks để tìm kiếm thông tin liên quan đến câu hỏi của người dùng.
- Kết hợp nhiều chunks để trả lời câu hỏi, như học sinh tổng hợp kiến thức từ nhiều phần của bài học để trả lời câu hỏi. RAG có thể kết hợp thông tin từ nhiều chunks khác nhau để đưa ra câu trả lời hoàn chỉnh và chính xác.
Điểm cực tiểu cục bộ và toàn cục trong gradient descent (Suy giảm độ dốc)
Học sinh thường phải tìm ra cách giải quyết vấn đề trong học tập, đôi khi là giải pháp tạm thời, đôi khi là giải pháp tối ưu. Việc này cũng giống như Gradient Descent tìm kiếm điểm tối ưu, có thể là điểm cực tiểu cục bộ hoặc toàn cục.
- Global minimum hay Giải pháp toàn diện lâu dài: Học sinh luôn mong muốn tìm ra phương pháp học tập tốt nhất. Tương tự, global minimum là điểm mà hàm mất mát đạt giá trị thấp nhất, tức là khi mô hình AI hoạt động tốt nhất, một giải pháp tối ưu cho bài toán.
- Local minimum hay Giải pháp tình thế: Học thuộc lòng công thức mà không hiểu rõ bản chất chính là giải pháp tình thế. Tương tự, local minimum là một điểm mà hàm mất mát đạt giá trị thấp, nhưng chưa phải thấp nhất, giống như một "giải pháp tình thế" cho mô hình AI.
- Gradient Descent có thể bị mắc kẹt tại local minimum giống như học sinh có thể mắc kẹt với giải pháp tình thế. Tương tự, Gradient Descent có thể không thể tìm thấy global minimum, dẫn đến mô hình AI chưa đạt hiệu suất tối ưu.
- Vượt qua local minimum tương tự việc học sinh tìm kiếm giải pháp toàn diện. Tương tự, trong ML, có nhiều kỹ thuật giúp Gradient Descent vượt qua local minimum để tìm global minimum, ví dụ như thay đổi learning rate, sử dụng momentum, hoặc các biến thể khác của Gradient Descent.
Loss Function và Gradient descent
- Loss function giống như Chênh lệch giữa điểm của học sinh và điểm tối đa của đáp án: Loss function đo lường mức độ "sai" của mô hình AI so với câu trả lời đúng (ground truth). Nói cách khác, loss function đo độ vênh giữa hiệu suất hiện tại của mô hình và hiệu suất hoàn hảo.
- Gradient Descent giống như Quá trình học sinh tìm cách cải thiện điểm số bằng cách học lại những phần chưa hiểu rõ, luyện tập thêm các dạng bài tập. Gradient Descent liên tục tìm cách để có giá trị của loss function thấp nhất, bằng cách thu hẹp khoảng cách giữa giá trị hiện tại của mô hình và ground truth.
Perceptron và Deep neural network
- Perceptron giống việc Học sinh học thuộc lòng một công thức đơn giản. Perceptron là một mô hình đơn giản, nhận đầu vào, nhân với trọng số (weights), cộng lại và đưa ra kết quả. Perceptron là thành phần cơ bản nhất của mạng nơ-ron.
- Deep Neural Network (DNN) (Mạng nơ-ron sâu) như việc Học sinh giải quyết bài toán phức tạp bằng nhiều bước suy luận. DNN gồm nhiều lớp perceptron xếp chồng lên nhau, cho phép xử lý thông tin phức tạp qua nhiều tầng, từ đó "học" được các đặc trưng trừu tượng và giải quyết các bài toán khó hơn perceptron đơn lẻ.
Có người cho rằng tất cả kỹ thuật tối ưu hóa đều được áp dụng như nhau giống như Mọi phương pháp học tập đều hiệu quả như nhau cho tất cả học sinh và mọi môn học. Đây là một nhận thức sai lầm!
Trong Machine Learning, không phải phương pháp nào cũng hiệu quả như nhau cho mọi tình huống.
- Các kỹ thuật tối ưu hóa khác nhau có tác động khác nhau giống như Cách học khác nhau cho hiệu quả khác nhau. Các kỹ thuật tối ưu hóa mô hình như nén mô hình (model compression), lượng tử hóa (quantization), và cắt tỉa (pruning) có tác động khác nhau đến hiệu suất của mô hình.
- Lựa chọn kỹ thuật tối ưu hóa cần cân nhắc nhiều yếu tố giống như Chọn phương pháp học phù hợp với bản thân, môn học và điều kiện. Tương tự, việc lựa chọn kỹ thuật tối ưu hóa mô hình cần phải cân nhắc kiến trúc mô hình, yêu cầu nhiệm vụ, giới hạn phần cứng, và mức độ hiệu suất chấp nhận được.
- Không có kỹ thuật tối ưu hóa nào là hoàn hảo như Không có phương pháp học tập nào là hoàn hảo. Mỗi kỹ thuật đều có những trade-off riêng.
Context window khác nhau giữa các LLMs tương tự khả năng nhớ bài của mỗi học sinh khác nhau
- LLMs có context window nhỏ giống như Học sinh chỉ nhớ được ít thông tin. Tương tự, LLMs với context window nhỏ chỉ có thể "nhớ" một lượng thông tin hạn chế. Khi lượng thông tin vượt quá context window, mô hình sẽ "quên" những thông tin còn lại (thường là giữa bài), dẫn đến kết quả không chính xác.
- LLMs có context window lớn giống như Học sinh có trí nhớ tốt. Tương tự, LLMs với context window lớn có thể xử lý được nhiều thông tin hơn, "nhớ" được ngữ cảnh rộng hơn, từ đó đưa ra câu trả lời chính xác và mạch lạc hơn.
- Lựa chọn LLM phù hợp giống như Giao bài toán phù hợp với khả năng của học sinh. Tương tự, việc lựa chọn LLM phù hợp với từng nhiệm vụ rất quan trọng. Đối với những văn bản dài, cần sử dụng LLMs có context window lớn.
- Tối ưu hóa context window giống như Rèn luyện trí nhớ: Học sinh có thể rèn luyện trí nhớ để giải các bài toán nhiều bước. Tương tự, các nhà nghiên cứu đang tìm cách để tăng context window của LLMs, giúp mô hình xử lý được nhiều thông tin hơn mà vẫn đảm bảo hiệu suất.
Một số khái niệm hay bị nhầm lẫn
- Nhầm lẫn ML và AI giống như Nhầm lẫn giữa “học” và “ứng dụng”.
- ‘Khớp’ (exact match) & ‘Khớp gần đúng’ (fuzzy match) giống như Tra cứu từ điển & Hiểu nghĩa: Lập trình truyền thống giống như tra từ điển, chỉ tìm kiếm kết quả khớp chính xác. ML giống như hiểu nghĩa của từ, có thể nhận ra các từ đồng nghĩa hoặc gần nghĩa.
- LLMs và Tìm kiếm giống như Học sinh & Thi được mở sách: LLMs kết hợp với tìm kiếm giống như học sinh được phép mở sách trong giờ kiểm tra.
- Lưu trữ kiến thức giống như Kiến thức nhập tâm: LLMs lưu kiến thức trong weights và biases, chứ không phải lưu trữ trong cơ sở dữ liệu riêng. Giống như học sinh đi thi chỉ lưu kiến thức trong đầu chứ không được mở sách.
- Vector Embedding và Caching giống như Nhập tâm tiếp thu kiến thức & Ghi nhanh ra giấy để không quên.
- Lưu cache phản hồi & Bảo mật giống như Chia sẻ bài làm & Gian lận.
Phần 3: Các bước triển khai thuật toán Machine Learning
Quy trình triển khai thuật toán học máy thường bao gồm 7 bước như sau:

Bước 1: Thu thập dữ liệu
- Số lượng và chất lượng dữ liệu quyết định mức độ chính xác của mô hình.
- Kết quả của bước này thường là một biểu diễn dữ liệu (như bảng dữ liệu), được sử dụng cho quá trình huấn luyện.
Bước 2: Tiền xử lý dữ liệu
- Trích xuất dữ liệu
- Làm sạch dữ liệu: Loại bỏ dữ liệu trùng lặp, sửa lỗi, xử lý giá trị thiếu, chuẩn hóa, chuyển đổi kiểu dữ liệu, v.v.
- Ngẫu nhiên hóa dữ liệu: Xóa bỏ ảnh hưởng của trình tự thu thập hoặc xử lý trước đó.
- Hình ảnh hóa dữ liệu: Giúp phát hiện các mối quan hệ quan trọng giữa các biến hoặc mất cân bằng lớp (cảnh báo lệch dữ liệu).
- Phân tách dữ liệu: Chia dữ liệu thành tập huấn luyện và đánh giá.
Bước 3: Lựa chọn Mô hình
Lựa chọn thuật toán phù hợp cho từng loại nhiệm vụ cụ thể.
Bước 4: Huấn luyện Mô hình
- Mục tiêu là trả lời chính xác câu hỏi hoặc đưa ra dự đoán với tỷ lệ đúng cao nhất.
Ví dụ: Hồi quy tuyến tính cần học giá trị
- Mỗi lần lặp trong quy trình này được coi là một bước huấn luyện.
Bước 5: Đánh giá Mô hình
- Sử dụng một hoặc nhiều thước đo để đánh giá hiệu quả khách quan của mô hình.
- Kiểm tra mô hình trên dữ liệu chưa từng được nhìn thấy trước đó để mô phỏng hiệu suất thực tế.
- Phân tách tập dữ liệu phù hợp: thường là 80/20 hoặc 70/30, tùy thuộc vào lĩnh vực, khả năng dữ liệu và đặc điểm tập dữ liệu.
Bước 6: Tinh chỉnh Tham số
- Tinh chỉnh các siêu tham số (hyperparameters) để cải thiện hiệu năng. Đây là một "nghệ thuật" hơn là khoa học chính xác.
- Các siêu tham số cơ bản bao gồm: số bước huấn luyện, tốc độ học, giá trị khởi tạo và phân phối, v.v.
Bước 7: Dự đoán kết quả
- Sử dụng dữ liệu trong tập kiểm tra (dữ liệu hoàn toàn chưa được mô hình sử dụng trước đó, với nhãn lớp đã biết) để kiểm tra hiệu suất thực tế.
- Đây là bước mô phỏng mức độ hiệu quả của mô hình trong môi trường thực tế.
Phần 4: Thách thức và giải pháp cho Machine Learning (ML)
Việc triển khai và duy trì các giải pháp machine learning hiệu quả đòi hỏi phải vượt qua nhiều thách thức. Dưới đây là những khó khăn chính cùng các giải pháp khả thi, bạn đọc có thể tham khảo:
1. Chất lượng dữ liệu
Dữ liệu không đầy đủ, nhiễu hoặc không cân đối có thể ảnh hưởng nghiêm trọng đến hiệu quả của các mô hình ML.
Giải pháp:
- Áp dụng các kỹ thuật làm sạch và tiền xử lý dữ liệu.
- Sử dụng phương pháp cân bằng dữ liệu như oversampling (tăng số lượng mẫu ở nhóm thiểu số) và undersampling (giảm số lượng mẫu ở nhóm đa số).
- Thực hiện kỹ thuật tăng cường dữ liệu (data augmentation) để cải thiện tính đa dạng và chất lượng dữ liệu.
2. Hiện tượng overfitting
Các mô hình phức tạp có thể học thuộc các mẫu đặc thù trong tập huấn luyện, dẫn đến hiệu suất kém khi áp dụng vào dữ liệu mới.
Giải pháp:
- Áp dụng các kỹ thuật regularization để hạn chế quá trình học quá mức.
- Sử dụng phương pháp cross-validation để đánh giá hiệu suất mô hình.
- Giảm độ phức tạp của mô hình và tăng kích thước tập dữ liệu huấn luyện.
3. Khả năng diễn giải mô hình
Các thuật toán ML, đặc biệt là mạng nơ-ron sâu, thường khó giải thích, gây khó khăn trong việc hiểu cách các quyết định được đưa ra.
Giải pháp: Sử dụng các công cụ như LIME (Local Interpretable Model-agnostic Explanations) và SHAP (SHapley Additive exPlanations) để cải thiện tính minh bạch của mô hình.
4. Bảo mật và quyền riêng tư
Việc sử dụng dữ liệu nhạy cảm trong ML làm dấy lên những lo ngại về bảo mật và quyền riêng tư.
Giải pháp:
- Áp dụng các kỹ thuật như differential privacy để bảo vệ dữ liệu cá nhân.
- Sử dụng federated learning để đảm bảo dữ liệu không rời khỏi thiết bị cá nhân.
- Tuân thủ các quy định và thực hành tốt nhất về bảo mật dữ liệu.
5. Khả năng mở rộng (Scalability)
Đào tạo và triển khai mô hình trên các tập dữ liệu lớn theo thời gian thực có thể là một thách thức lớn.
Giải pháp:
- Sử dụng tính toán phân tán và hạ tầng đám mây.
- Áp dụng các framework ML có khả năng mở rộng để xử lý khối lượng dữ liệu lớn một cách hiệu quả.
Phần 5: Xu hướng tương lai của Machine Learning: Cơ hội và đổi mới
Những tiến bộ trong lĩnh vực Machine Learning (ML) đang mở ra những cơ hội mới, đồng thời thúc đẩy sự phát triển liên tục của công nghệ này. Một số xu hướng nổi bật bao gồm:

Tự động hóa Machine Learning (AutoML)
Công nghệ AutoML cho phép tự động hóa các nhiệm vụ quan trọng, từ lựa chọn mô hình đến tối ưu hóa siêu tham số. Điều này không chỉ giúp ML trở nên dễ tiếp cận hơn mà còn nâng cao hiệu suất vận hành, đặc biệt phù hợp với các doanh nghiệp cần ứng dụng nhanh chóng.
Deep Learning
Sự phát triển của các kiến trúc mạng nơ-ron tiên tiến như Transformers đang cách mạng hóa các lĩnh vực như xử lý ngôn ngữ tự nhiên (NLP) và tạo hình ảnh. Những ứng dụng mới, từ sáng tạo nội dung tự động đến phân tích dữ liệu chuyên sâu, đang tạo ra nhiều cơ hội đột phá cho doanh nghiệp.
AI có thể giải thích (Explainable AI)
Nhu cầu về các mô hình Machine Learning minh bạch và dễ hiểu đang thúc đẩy sự phát triển của các kỹ thuật giải thích mới. Điều này đặc biệt quan trọng trong việc xây dựng niềm tin và đảm bảo sự chấp nhận của các giải pháp AI trong môi trường doanh nghiệp.
AI và đạo đức
Nhận thức ngày càng cao về các vấn đề đạo đức liên quan đến AI đang khuyến khích việc thiết lập các hướng dẫn và quy định để đảm bảo công nghệ này được sử dụng một cách công bằng, trách nhiệm và bền vững.
Học liên tục và thích ứng (Continuous and Adaptive Learning)
Trong các môi trường biến động, những mô hình có khả năng học hỏi liên tục và thích ứng với dữ liệu mới mà không cần đào tạo lại toàn diện sẽ trở thành yếu tố quan trọng, mang lại lợi thế cạnh tranh đáng kể.
Những xu hướng này dự báo một tương lai mà Machine Learning sẽ tích hợp sâu hơn vào cuộc sống hàng ngày, thúc đẩy đổi mới và tối ưu hóa quy trình trên nhiều lĩnh vực, đồng thời giải quyết những thách thức hiện tại. Hy vọng bài viết này đã giúp bạn có cái nhìn tổng quan hơn về lĩnh vực này. Nếu bạn muốn tìm hiểu sâu hơn, hãy để lại bình luận bên dưới, chúng tôi sẽ giúp bạn giải đáp. SlimCRM luôn sẵn sàng đồng hành cùng bạn trên con đường chinh phục Machine Learning.
Nguồn tham khảo: Group Facebook Bình dân Học AI
